Kickstarter Projects — Do They Succeed?
A Data Science Perspective

Kickstarter. Most of us have seen Kickstarter projects be that in social media ads, blogposts or search results. Hell, you can even be one of those who treat Kickstarter like Instagram and browse it daily.
For the small portion of readers who don’t know what Kickstarter is, Kickstarter is a platform for launching your own products or services through crowdfunding. You can create a page with information about your creative product which can be anything from a tech product to a art masterpiece. You then set a funding goal. This money is then used for different aspects related to making that product come to life.
As cool as it sounds, Kickstarter projects are not guaranteed to succeed. Through this article, we’ll analyze the past performances of Kickstarter projects based on year of release, category, funding goal etc. The dataset we’re using is a Kaggle dataset comprising information about more than 300,000 Kickstarter projects up to the year 2018. Special thanks to Mickaël Mouillé for making this dataset a reality.
A quick shoutout to www.jovian.ai and its founder Aakash NS ,who is also the instructor of ‘Data Analysis with Python: Zero to Pandas’ which is a free of cost course to get started with data science. The course is extremely thorough and easy to understand. In fact, this project is part of the same course. Do check it out if you want to get started with Data Science.
I have compiled my class notes in a Notion notebook folder which can be a handy guide for you. Do check it for a reference while going through the code.
If you want to play around with the code, an executable Jupyter Notebook can be found here. Without further ado, let’s get started.
Downloading the Dataset
Let’s start by downloading the dataset from Kaggle. Here we use the opendatasets library made for python to download the same. By passing the URL of the Kaggle page ofthe dataset to opendatasets.download(), we will download the dataset to our Jupyter notebook directly.
Let's begin by downloading the data, and listing the files within the dataset.
dataset_url = 'https://www.kaggle.com/kemical/kickstarter-projects'import opendatasets as od
od.download(dataset_url)
The dataset has been downloaded and extracted.
data_dir = './kickstarter-projects'import os
os.listdir(data_dir)
Output: We have listed the files that have been downloaded. We will use the updated 'ks-projects-201801.csv' file for our use.
Out :['ks-projects-201612.csv', 'ks-projects-201801.csv']Data Preparation and Cleaning
While working with real world raw data, it is necessary to prepare the data for our analysis. There could be wrong values, missing values in the raw data which needs to be dealt with. Along with that, we might want to add new columns which are useful for our analysis to the dataset or we might want to merge a few datasets together, this should be done as a preliminary step.
In our case, let’s start by converting the dataset into a Pandas dataframe. Pandas is a python library which gives us handy functions for data cleaning, merging, operations etc. It creates an object called as Data Frame which is basically the data displayed in tabular form. If you know a little bit of coding, a Data Frame can be considered as a dictionary of lists.
We can read different types of files eg. CSV, JSON, XLSX etc. and create a Data Frame using the same. To know more about Pandas, check my Notion notebook.
#importing the pandas libraryimport pandas as pd#reading the CSV file that we downloadedkickstarter_data = pd.read_csv('./kickstarter-projects/ks-projects-201801.csv')
Let's take a look at our dataset
We can check the shape of our dataset using the .shape method. It returns a tuple in the form (Number of Rows, Number of Columns) As we can see, the dataset contains information about more than 300000 Kickstarter projects.
We don’t really need the ID and name columns as they don't play any part in our analysis. We can remove columns by passing a list of their names to .drop method of the Data Frame. We have to provide axis argument where 0 = rows and 1 = columns.
kickstarter_data = kickstarter_data.drop(['ID','name'], axis =1)Going through the Kaggle discussion, it seems that the pledged column contains the amount pledged by crowd in the currency that it is listed in. It is important that the amount for all the rows is converted to one currency for accurate analysis. The amount converted to USD is listed in two columns i.e usd pledged and usd_pledged_real. Similar can be said about the goal column. Going through more discussions on Kaggle page, we can assume that usd pledged column contains conversion made using Kickstarter which contains a lot of errors. The usd_pledged_real and usd_goal_real column is converted using more accurate Fixer.io API, which we will use. Thus we can drop pledged, goal and usd pledged columns.
kickstarter_data = kickstarter_data.drop(['pledged', 'goal', 'usd pledged'], axis =1)Now let’s see how the Data Frame looks like.
The exact time to the accuracy of seconds is not really important for us in launched and deadline column. We can just extract the year, month and day of launch for the same. First let's convert the columns to datetime objects. Datetime objects are recognized by python as dates which will help us to do further operations.
#Converting to DateTime objectspd.to_datetime(kickstarter_data.launched,format='%Y-%m-%d', errors = 'coerce');
pd.to_datetime(kickstarter_data.deadline,format='%Y-%m-%d', errors = 'coerce' );#Extracting year, month and day of the weekkickstarter_data['launched_year'] = pd.DatetimeIndex(kickstarter_data['launched']).year
kickstarter_data['launched_month'] = pd.DatetimeIndex(kickstarter_data['launched']).month
kickstarter_data['launched_day'] = pd.DatetimeIndex(kickstarter_data['launched']).weekday#Dropping the deadline column as we don't need it.kickstarter_data = kickstarter_data.drop(['deadline'], axis = 1)
With this, we have completed preparing our data for the analysis. Now, let’s explore the characteristics of the data.
Exploratory Analysis and Visualization
We can now use the Data Frame to get interesting insights into the data. Let’s compute a few things that will tell us more about the data. For doing so, we will be using two data visualization libraries, namely matplotlib and seaborn. These libraries contain useful methods to plot graphs and charts. Matplotlib provides basic functionality while Seaborn builds on top of matplotlib to give advanced functionality in very few lines of code.
Learn more about matplotlib and seaborn here. You can also go through the documentation for both by simply visiting their respective websites.
Data insights using .describe()
Before plotting graphs, Let’s first get some insights about our dataset using the .describe() method provided by pandas.
This gives us some interesting preliminary insights into our data. As we can see,
- The average goal is around 45000 USD.
- The average pledged is around 9000 USD which is way less that our average goal.
- The data for goal varies more with respect to the mean than the data for amount pledged.
- We have data varying all the way from 1970 to 2018. Though 75% of data is between 2013 and 2019.
- On an average, around 105 people have backed a Kickstarter project but the variance is very high. In fact, 75% of projects have had less than 56 backers.
Let’s importmatplotlib.pyplot and seaborn.
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
sns.set_style('darkgrid')
matplotlib.rcParams['font.size'] = 14
matplotlib.rcParams['figure.figsize'] = (9, 5)
matplotlib.rcParams['figure.facecolor'] = '#00000000'Comparing number of projects per year using bar chart
Let’s plot a basic bar graph that shows number of projects per year. Here we will first sort the data according to the year and month by using .groupby() function. Then We create a new data frame containing the launched_year series, launched_month series and the count which we found using .size() function. We name this final column as counts.
#Sorting the data into groups kickstarter_obj = kickstarter_data.groupby(['launched_year', 'launched_month'])#Getting counts of projects in a group using .size()
kickstarter_by_year = kickstarter_obj.size().reset_index(name='counts')
This is how the newly created Data Frame looks like :
Now that we have the data frame, let’s plot the bar graph. Here we’re using the barplot() function from the seaborn library. As arguments, we'll provide launched_year series for x-axis, counts series for y-axis and a data argument. Seaborn has a good support for pandas. By providing a data frame in the 'data' argument, seaborn will automatically find the x and y series' from the given data frame.

As we can see above,
- The number of projects on Kickstarter seem to have peaked in 2015.
- The data for 2018 is incomplete so we should not take it as definitive. This is assuming that all Kickstarter projects from 2009 onwards are included in the dataset.
- The data from 1970 seems to be bad or insignificant data.
Plotting a heatmap for yearly and monthly distribution of projects
Now let’s prepare our data for a heatmap that shows us the counts in terms of months and years. This time we will use the same groupby object that we created for the previous graph.
#sorting the data into groups by year and monthkickstarter_by_year_month = kickstarter_obj.size().reset_index(name='counts')
Now we use a special funcion provided by pandas called .pivot() which converts the Data Frame into a 2D matrix, taking first argument (series) as rows, 2nd argument being columns and third argument being the values corresponding to series 1 and series 2. Check it out below.
#Creating a 2D Matrix
kickstarter_by_year_month = kickstarter_by_year_month.pivot('launched_year', 'launched_month', 'counts')Now we plot a heatmap by passing the dataset to the heatmap() function provided by seaborn. Theannot argument can be set to True if you want to show the values in the blocks.

The above graphs tells us more about the data.
- The data collection started in April 2009.
- It seems like the data entries without launch date were initialized to January 1970 or “Unix Time”. We should ignore those for statistics involving dates, for other statistics, these entries are still relevant.
- The data available is only up to January 2018.
- As the bar plot suggested amount of projects peaked between 2014 and 2015. With maximum projects coming in July 2014.
- There seems to be increase in number of projects during October and November as compared to August of every year and a decrease in December. We can find why so with research.
Goal amount vs pledged amount using line chart
Now, let’s explore how the amount pledged by backers compares to the goal set, for every year. First we will group the data by year and then compute the mean using mean() for every year. We will have to reset the index again as the groupby() function sets the series that we use to group the data as the index.
#Creating groups and computing mean for every group
kickstarter_data_mean = kickstarter_data.groupby(kickstarter_data.launched_year).mean()#Resetting the index
kickstarter_data_mean = kickstarter_data_mean.reset_index('launched_year')
This is how our newly created data frame looks.
We’ll use Seaborn to plot the line plots by passing in both the series’ to sns.lineplot() function. We can plot both the lines in same graph by writing both sns.lineplot() functions in the same cell as seen below. we will limit the x axis values from 2009 to 2018 as we found out that rows with launched_year = 1970 were defaulted to that value and that would not give us accurate results.

This is a very interesting chart. It tells us that,
- As the lines do not intersect at any point, the mean amount pledged does not exceed the mean goal for any year.
- The mean goal, just like number of projects, seems to have peaked in 2015 before going down in 2016, 2017.
- The line of mean amount pledged is fairly flat indicating that even though projects on the platform increased in 2013–2015, the amount pledged fairly remained the same for any project. For being more sure about this, let’s quickly plot the cumulative sum data instead of mean.
kickstarter_data_sum = kickstarter_data.groupby(kickstarter_data.launched_year).sum()
kickstarter_data_sum = kickstarter_data_sum.reset_index('launched_year')
As we can see, even the line for cumulative sum of amount pledged remains flat for all the years where the goal amount peaked. This might have made many projects fail in the peak years, making the goal amount go down again.
Yearwise status comparison
Let’s see how the status of projects (successful, failed etc.) compare over the year using bar graph. First we will group the data based on state and launched_year. Then we will count the numbers falling in every category using size() and then change the index to a column named counts finally we will plot the bar plot using seaborn. we will provide launched_year for X axis, counts for Y axis and we will set the hue to state. Using this, different bars for each state corresponding to every year will be plotted.
#Grouping the data and getting counts
kickstarter_state = kickstarter_data.groupby([kickstarter_data.state, kickstarter_data.launched_year]).size().reset_index(name='counts')
As we can see,
- Failed projects are more than successful projects almost every year.
- As previous graphs told us, while the amount of goal increased during 2014–2015, the amount pledged remained pretty much similar to previous years. This in-turn increased the gap in this graph between number of successful projects and number of failed projects as the goal was not met.
- Until 2014, number of successful projects was on par with number of failed projects.
- Though if we account cancelled + suspended + failed = unsuccessful, number of unsuccessful projects for every single year is more than number of successful projects.
Pie chart to analyze the overall success rate
Now that we pretty much know that more projects on Kickstarter are unsuccessful as compared to the successful ones, let’s calculate the success rate of the projects.
First we will group the dataset based on state and then count the number of projects for each state before plotting the pie chart.
We should drop the live projects as we don’t know if they eventually succeeded. We will also create a percentage column to display percentage of every state in the chart. round() function takes the value and rounds it down to nearest number with specified (here 2) number of decimals.
Now let’s plot the pie chart.

We can now say that out of all the projects in the dataset, 35.64% have succeeded while 52.6% have failed. Other states along with failed can be deemed as “unsuccessful” as percentage of ‘undefined’ is negligible. On Kickstarter, unsuccessful projects are more than successful projects.
Deep Dive
Now we basically know fundamental details about the dataset we have. It’s interesting how just a few lines of code can make a huge dataset containing raw data and lots of values can be made sense of. The visualizations help to a great extend. We started with knowing nothing about the data except the columns it contained. Now just a few moments later, we pretty much know the quantitative answer of the question we asked in the title. It’s really fascinating.
Now we can answer a few more interesting questions about the dataset which can help us understand the data even better.
Q1: Which main categories have more successful projects than failed ones?
To answer this, we can group the data based on main_category and state and count the items for each row. We’ll call that column projects. Then we can plot a bar chart with projects on the X axis and main_category on the Y axis with state set as hue to compare and find out the answer.
kickstarter_category = kickstarter_data.groupby([kickstarter_data.main_category, kickstarter_data.state]).size().reset_index(name = 'projects')
Answer — Comics, Dance, Music and Theatre are the main categories where successful projects are more than failed projects. Insights :
- Looks like performance arts projects are succeeding more than they are failing.
- Art, Crafts, Design, Fashion, Film and Video, Food, Games, Journalism, Photography, Publishing and Technology have more failed projects than successful ones.
- Film and Video has the largest number of failed projects.
Q2: Which category had the most projects?
Let’s group the data based only on main_category and then use the size() function to calculate the sum. Then we'll plot a basic bar chart.

Answer — Clearly film and video projects are maximum followed by music, which is followed by publishing and technology.
Q3: Which category has the highest goal amount per project?
For that, we will group the data based on main_category and compute the sum of usd_goal_real for every column before dividing it by number of projects for each category. Finally, we will plot a bar chart to compare the same.
kickstarter_category2 = kickstarter_data.groupby(kickstarter_data.main_category).sum().reset_index('main_category')
kickstarter_category2['goal_per_project'] = kickstarter_category2['usd_goal_real'] / kickstarter_category1['projects']
Answer — The most amount of goal per category in USD is for technology. This is a really interesting chart.
- Even though number of projects is maximum for Film and Video, goal set by the project creator for technology exceeds that of any other category.
- Journalism comes second with Film and Video following it.
- The least goal is for dance.
Let’s compute the same for amount pledged and add dots for goals using sns.scatterplot() for comparing.

- Interestingly, pledged amount per project for design exceeds that of technology.
- Games which was not prominent in previous statistics suddenly rises to third spot in the graph.
- Goal amount per project for every category is higher than the pledged amount per project.
- It is still not clear where the difference between goal per project and pledged per project is maximum.
Q4: Which category has the maximum difference in goal amount and pledged amount per project?
We will simply compute the difference between goal_per_project and pledged_per_project and then plot the graph of difference.
kickstarter_category2['Goal_pledged_difference'] = kickstarter_category2['goal_per_project'] - kickstarter_category2['pledged_per_project']
Answer — The difference between Goal per Project and Pledged per Project is maximum for Journalism.
- Journalism is followed by Technology and Film and Video.
- The difference is lowest for dance followed by photography.
Q5: Which category has maximum pledged amount per backer?
We will calculate this by dividing usd_pledged_real by backers for every category. Finally we will plot a bar chart.
#Calculating amount pledged per backer
kickstarter_category3['pledged_per_backer'] = kickstarter_category3['usd_pledged_real'] / kickstarter_category3['backers']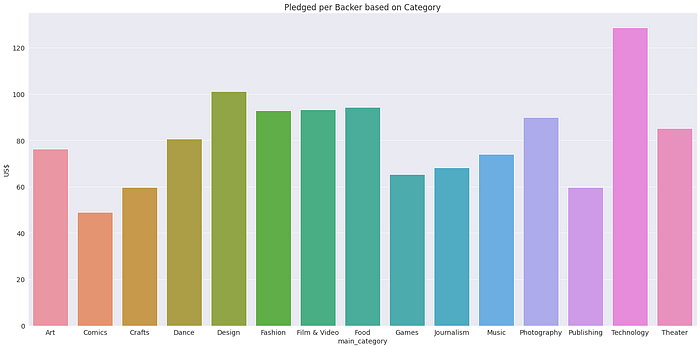
Answer — Pledged per Backer is maximum for Technology.
- Technology category is a clear standout here with more than USD 120 per backer.
- Comics has the lowest pledged amount per backer with just over USD 50 per backer.
Conclusion
Kickstarter is an amazing platform for crowdfunding innovative and creative projects. It is the truth that most of the projects fail rather than succeeding but looking at it positively, nearly 36% of projects have succeeded on kickstarter. Businesses do fail in real life thus it is important to compare success rate with other modes of raising capital. This can be done as a future work. Bottom line is, even though the goal set by most projects is not achieved on kickstarter, it is an easy way to raise capital. It might even be that people who launch projects set the goal higher than necessary. We need more research to imply that.
The bigger picture is, we learned a lot about data today. How raw data can be made sense of, how visualizations play an important role in analyzing data and how great python libraries are! :)
References (Special Thanks)
- My Notion Notebook : https://www.notion.so/58cf2b852a67449ebdea6a541db0ab90?v=d1c79b65c16741079e11e99102896b29
- Matplotlib documentation : https://matplotlib.org/api/index.html
- Seaborn Documentation : https://seaborn.pydata.org/
- www.stackoverflow.com
- www.quora.com
- Jovian.ai and Aakash NS : www.jovian.ai/aakashns
- Jovian.ai Zero to Pandas course : https://jovian.ai/learn/data-analysis-with-python-zero-to-pandas
- Kaggle Dataset : https://www.kaggle.com/kemical/kickstarter-projects
Future Work
- Comparing success rate with other means of raising capital.
- Comparison based on country.
- Kickstarter vs Indiegogo
- Predicting if a Kickstarter project would succeed or not.
