

The Levenshtein distance is a text similarity measure that compares two words and returns a numeric value representing the distance between them. The distance reflects the total number of single-character edits required to transform one word into another. The more similar the two words are the less distance between them, and vice versa. One common use for this distance is in the autocompletion or autocorrection features of text processors or chat applications.
Previously we discussed how the Levenshtein distance works, and we considered several examples using the dynamic programming approach.
In this tutorial the Levenshtein distance will be implemented in Python using the dynamic programming approach. We'll create a simple application with autocomplete and autocorrect features which use the Levenshtein distance to select the "closest" words in the dictionary.
The sections covered in this tutorial are as follows:
- Creating the
distancesmatrix - Initializing the
distancesmatrix - Printing the
distancesmatrix - Calculating distances between all prefixes
- Dictionary search for autocompletion/autocorrection
Let's get started.
Bring this project to life
Creating The Distance Matrix
Using the dynamic programming approach for calculating the Levenshtein distance, a 2-D matrix is created that holds the distances between all prefixes of the two words being compared (we saw this in Part 1). Thus, the first thing to do is to create this 2-D matrix.
We are going to create a function named levenshteinDistanceDP() that accepts 2 arguments named token1 and token2, representing the two words. It returns an integer representing the distance between them. The header of this function is as follows:
levenshteinDistanceDP(token1, token2)Given two words of lengths m and n, and based on the steps discussed in the previous tutorial, the first thing to do is to create a 2-D matrix of integers of size (m+1, n+1) or (n+1, m+1) based on whether the first word represents the rows or the columns. It doesn't matter which word is used for what, but you do need to be consistent since the rest of the code depends on this choice.
The next line creates such a matrix in a variable named distances (in this case the first word represents the rows and the second word represents the columns). Note that the length of the string is returned using the length() function.
distances = numpy.zeros((len(token1) + 1, len(token2) + 1))Initializing The Distance Matrix
The next step is to initialize the first row and column of the matrix with integers starting from 0. We'll do that with the for loop shown below, which uses a variable named t1 (shortcut for token1) that starts from 0 and ends at the length of the second word. Note that the row index is fixed to 0 and the variable t1 is used to define the column index. By doing that, the first row is filled with values starting from 0.
for t1 in range(len(token1) + 1):
distances[t1][0] = t1For initializing the first column of the distances matrix another for loop is used, as given below. There are two changes compared to the previous loop. The first is that the loop variable is named t2 rather than t1 to reflect that it starts from 0 until the end of the argument token2. The second change is that the column index of the distances array is now fixed to 0, while the loop variable t2 is used to define the index of the rows. This way the first column is initialized by values starting from 0.
for t2 in range(len(token2) + 1):
distances[0][t2] = t2Printing The Distance Matrix
After initializing both the first row and first column of the distances array, we'll use a function named printDistances() to print its contents using two for loops. It accepts three arguments:
- distances: The 2-D matrix holding the distances.
- token1Length: Length of the first word.
- token2Length: Length of the second word.
def printDistances(distances, token1Length, token2Length):
for t1 in range(token1Length + 1):
for t2 in range(token2Length + 1):
print(int(distances[t1][t2]), end=" ")
print()Below is the complete implementation up to this point. The levenshteinDistanceDP() function is called after passing the words kelm and hello, which were used in the previous tutorial. Since we're not done yet, it will currently return 0.
import numpy
def levenshteinDistanceDP(token1, token2):
distances = numpy.zeros((len(token1) + 1, len(token2) + 1))
for t1 in range(len(token1) + 1):
distances[t1][0] = t1
for t2 in range(len(token2) + 1):
distances[0][t2] = t2
printDistances(distances, len(token1), len(token2))
return 0
def printDistances(distances, token1Length, token2Length):
for t1 in range(token1Length + 1):
for t2 in range(token2Length + 1):
print(int(distances[t1][t2]), end=" ")
print()
levenshteinDistanceDP("kelm", "hello")Inside the levenshteinDistanceDP() function, the printDistances() function is called for printing the distances array according to the next line.
printDistances(distances, len(token1), len(token2))Here is the output.
0 1 2 3 4 5
1 0 0 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0 Up to this point, the distances matrix is successfully initialized. In the next section we'll calculate the distances between all prefixes of the two words.
Calculating Distances Between All Prefixes
To calculate the distances between all prefixes of the two words, two for loops are used to iterate through each cell in the matrix (excluding the first row/column).
for t1 in range(1, len(token1) + 1):
for t2 in range(1, len(token2) + 1):Inside the loops the distances are calculated for all combinations of prefixes from the two words. Based on the discussion in the previous tutorial, the distance between two prefixes is calculated based on a 2 x 2 matrix as shown in the next figure. Such a matrix always has three known values and just one missing value which is to be calculated.
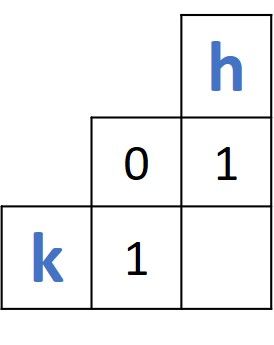
If the two characters located at the end of the two prefixes being compared are equal, then the distance is equal to the value in the top-left corner of the 2 x 2 matrix. This is implemented in the next if statement.
if (token1[t1-1] == token2[t2-1]):
distances[t1][t2] = distances[t1 - 1][t2 - 1]If the two characters are not equal, then the distance in the current cell is equal to the minimum of the three existing values in the 2 x 2 matrix after adding a cost of 1. An else block is added to the previous if statement to calculate such a distance according to the following code.
if (token1[t1-1] == token2[t2-1]):
distances[t1][t2] = distances[t1 - 1][t2 - 1]
else:
a = distances[t1][t2 - 1]
b = distances[t1 - 1][t2]
c = distances[t1 - 1][t2 - 1]
if (a <= b and a <= c):
distances[t1][t2] = a + 1
elif (b <= a and b <= c):
distances[t1][t2] = b + 1
else:
distances[t1][t2] = c + 1Here are the two for loops after adding this if-else block.
for t1 in range(1, len(token1) + 1):
for t2 in range(1, len(token2) + 1):
if (token1[t1-1] == token2[t2-1]):
distances[t1][t2] = distances[t1 - 1][t2 - 1]
else:
a = distances[t1][t2 - 1]
b = distances[t1 - 1][t2]
c = distances[t1 - 1][t2 - 1]
if (a <= b and a <= c):
distances[t1][t2] = a + 1
elif (b <= a and b <= c):
distances[t1][t2] = b + 1
else:
distances[t1][t2] = c + 1At this moment, the levenshteinDistanceDP() function is almost complete except for returning the calculated distance between the two words. This distance is located at the bottom-right corner of the distances matrix and is returned according to this line.
return distances[len(token1)][len(token2)]The implementation of the levenshteinDistanceDP() function is now 100% complete. Here's the full code.
def levenshteinDistanceDP(token1, token2):
distances = numpy.zeros((len(token1) + 1, len(token2) + 1))
for t1 in range(len(token1) + 1):
distances[t1][0] = t1
for t2 in range(len(token2) + 1):
distances[0][t2] = t2
a = 0
b = 0
c = 0
for t1 in range(1, len(token1) + 1):
for t2 in range(1, len(token2) + 1):
if (token1[t1-1] == token2[t2-1]):
distances[t1][t2] = distances[t1 - 1][t2 - 1]
else:
a = distances[t1][t2 - 1]
b = distances[t1 - 1][t2]
c = distances[t1 - 1][t2 - 1]
if (a <= b and a <= c):
distances[t1][t2] = a + 1
elif (b <= a and b <= c):
distances[t1][t2] = b + 1
else:
distances[t1][t2] = c + 1
printDistances(distances, len(token1), len(token2))
return distances[len(token1)][len(token2)]The next line calls the levenshteinDistanceDP() function to print the distances matrix and return the final distance between the two words.
distance = levenshteinDistanceDP("kelm", "hello")The output should look like that shown below.
0 1 2 3 4 5
1 1 2 3 4 5
2 2 1 2 3 4
3 3 2 1 2 3
4 4 3 2 2 3
3The distance between "kelm" and "hello" is 3.
In the next section we'll build on top of this function to allow the user to enter a word, and the top closest words (based on a dictionary search) will be returned.
Dictionary Search for Word Autocompletion and Autocorrection
One application of the Levenshtein distance is to help the writer write faster by automatically correcting typos or completing words. In this section we'll experiment with a small version of the English dictionary (which contains just 1,000 common words) to complete this task. The dictionary is available for download at this link. It is a text file from which we will read and extract each word, then call the levenshteinDistanceDP() function, and finally return the best-matched words. Of course, you could always expand this implementation with a full-sized dictionary of your choosing.
The block of code below creates a function named calcDictDistance() which accepts two arguments, reads the dictionary, and calculates the distance between the search word and all words in the dictionary.
The first argument is named word and represents the search word to be compared by the words in the dictionary. The second argument is named numWords which accepts the number of matched words to be filtered.
Currently, the calcDictDistance() function just reads the text file at the specified path using the open() function. The variable line iteratively holds each line (i.e. word) in the dictionary returned using the readLines() method. The calcDictDistance() function does not yet return anything, but we will soon change it to return a list holding the best-matched words.
def calcDictDistance(word, numWords):
file = open('1-1000.txt', 'r')
lines = file.readlines()
for line in lines:
print(line.strip()) Next is to compare the search word with each word in the dictionary, calculate a distance, and store all distances in a list named dictWordDist. Its length is 1,000 because the dictionary contains 1,000 words.
The dictWordDist list is of type String and holds both the distance and the dictionary word separated by -. For example, if the distance between the search word and the word "follow" is two, then the entry saved in the dictWordDist list will be 2-follow. Later, the distance will be separated from the word using the split() method.
def calcDictDistance(word, numWords):
file = open('1-1000.txt', 'r')
lines = file.readlines()
file.close()
dictWordDist = []
wordIdx = 0
for line in lines:
wordDistance = levenshteinDistanceMatrix(word, line.strip())
if wordDistance >= 10:
wordDistance = 9
dictWordDist.append(str(int(wordDistance)) + "-" + line.strip())
wordIdx = wordIdx + 1The function is now ready for filtering the dictWordDist list for returning the best-matched words based on the distance. The complete function is shown below. A list named closestWords is defined to hold the best-matched words. Its length is set to the value inside the numWords argument.
The dictWordDist list is sorted to leave the best-matched words at the top of the list. Inside a for loop with a number of iterations equal to the value of the numWords argument, the dictWordDist list is indexed to return a string holding the distance and the word separated by -.
def calcDictDistance(word, numWords):
file = open('1-1000.txt', 'r')
lines = file.readlines()
file.close()
dictWordDist = []
wordIdx = 0
for line in lines:
wordDistance = levenshteinDistanceMatrix(word, line.strip())
if wordDistance >= 10:
wordDistance = 9
dictWordDist.append(str(int(wordDistance)) + "-" + line.strip())
wordIdx = wordIdx + 1
closestWords = []
wordDetails = []
currWordDist = 0
dictWordDist.sort()
print(dictWordDist)
for i in range(numWords):
currWordDist = dictWordDist[i]
wordDetails = currWordDist.split("-")
closestWords.append(wordDetails[1])
return closestWordsThis string is then split using the split() method which returns a list with two elements: the first is the distance, and the second is the word. The word is inserted into the closestWords list which is then returned by the calcDictDistance() function. Now this function is considered complete.
Here is an example of calling the calcDictDistance() function. The search word is pape and the number of matches is 3.
print(calcDictDistance("pape", 3))The output of the above code is given below. The Levenshtein distance successfully helped in making good suggestions, especially for the first two words. By doing that, the user does not have to enter the complete word and by just entering some characters that discriminate the word, the program is able to make suggestions that help in either autocompletion or autocorrection.
page
paper
ageConclusion
This tutorial discussed the Python implementation of the Levenshtein distance using the dynamic programming approach. We started by creating a function named levenshteinDistanceDP() in which a 2-D distance matrix is created for holding the distances between all prefixes of two words. This function accepts the two words as input, and returns a number representing the distance between them.
Another function named calcDictDistance() is created to build a useful application of the Levenshtein distance in which the user supplies a word and the program returns the best-matched words based on a dictionary search. This helps in autocompleting or autocorrecting text while a user is typing.










